Architecture
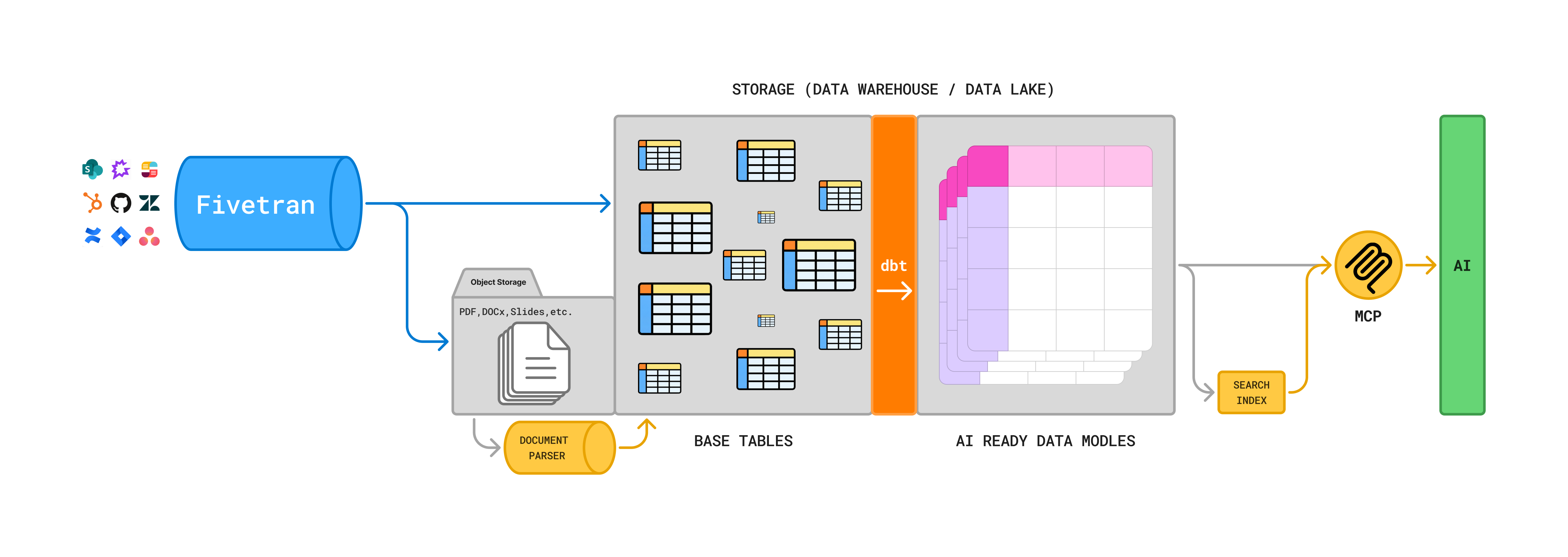
Triage is built on top of the modern data stack, designed to provide reliable, up-to-date, and secure knowledge search for support teams. By leveraging Fivetran's enterprise-grade connectors, dbt's data transformations, and Triage's AI capabilities, we unify scattered business context into a clean, AI-ready knowledge base.
This architecture ensures easy search and access to complete information from all your workplace applications. Unlike federated search, which often suffers from usage rate limits, gaps due to retention policies, and complex APIs, Triage delivers consistent, high-quality results by searching against a centralized, optimized, and indexed data repository.
Powered by Fivetran
Your business context is replicated from source systems like ticketing platforms, wikis, and file stores (Zendesk, Confluence, SharePoint etc.) into a central data repository using Fivetran connectors. Fivetran provides an enterprise-grade foundation that keeps your data complete and current—automatically syncing documents, metadata, and schema changes through efficient incremental updates and robust reliability mechanisms, all protected by enterprise-grade security.
AI-ready data models
Your business context is modeled into an AI-ready format—denormalizing related entities, dereferencing links and IDs, chunking large documents into meaningful sections, and structuring fields to reduce tokens. This removes the need for LLMs to traverse complex schemas and knowledge graphs, which is often slow and error-prone. By taking this heavy lifting off the LLMs, we make their outputs faster, more accurate, and more consistent.
Delivering consistently high-quality search
Triage ensures your search results remain consistent and high-quality by applying the following strategies.
Up-to-date knowledge bases
The knowledge repository is continuously curated and refreshed using Fivetran connectors, so Triage searches against the latest tickets, chats, and documents—not a snapshot from weeks or months ago.
Data models optimized for LLMs
Structured relational data is reshaped into AI-ready formats that are easier for large language models to work with. By denormalizing complex relationships (for example, linking a Jira ticket with its comments and related issues) before indexing, retrieval returns richer, more complete context—so both humans and AI get a comprehensive view of the data with minimal extra lookups.
Incremental indexing
Updates to your data are indexed incrementally. This means changes in your source systems show up more quickly and efficiently in search results.
No gaps in knowledge at runtime
Because your data is centralized ahead of time, Triage is not impacted by API rate limits, source retention policies, or temporary source downtime—everything needed for retrieval is already readily available.
Truly own your data
By default, Triage manages storage and pipelines for you so your support team can get up and running quickly. If you prefer, you can also run Triage on top of your own warehouse and connectors, so it works with your existing open data infrastructure instead of locking data inside a black-box AI endpoint.
With BYO Fivetran, the same clean, modeled tables that power Triage are stored in open, reusable formats—so they can also feed analytics, forecasting, BI, audits, or new AI workloads. This “build once, reuse everywhere” approach avoids vendor-specific schemas and keeps you from creating yet another siloed copy of your data.